This is a personal study on the public Kaggle credit-card fraud dataset, written as a structured analytical exercise rather than a product story. The dataset is heavily imbalanced (0.17% positive class), which is exactly the setting where a model can post strong headline metrics while still leaving most of the financial loss on the table. The objective here is narrow and explicit: translate that imbalance into decisions that protect organisational value, by combining leakage-safe preparation, calibrated probabilities, and a cutoff selected for net dollars saved rather than convention. No claims of production deployment, no synthetic operational drama. Just the analysis, the numbers, and the business reading of those numbers.
Start with the business reality, not the model
Before any algorithm is fit, the raw counts already frame the problem. The training window covers 227,845 transactions over roughly 48 hours, including 394 confirmed fraud cases. Fraud is 0.173% of the stream. That imbalance is the central constraint, because a model can look 'accurate' while still missing the exact rare events that carry the financial loss.

The dollar context matters equally. The same slice carries roughly $49,483 in fraud exposure with a worst-single-fraud of $2,126. The question is therefore not only 'how many frauds are caught?' but also 'which fraud dollars are recovered, and which expensive misses still slip through?'
Why dollars, not counts
A model tuned to catch the most fraud cases is not the same model that recovers the most dollars. The 26-point gap between case recall and dollar recall in the final results is the entire reason this analysis exists.
EDA as the backbone: where fraud actually lives
The first strong signal is temporal. Normal transaction volume rises through the commercial day, but the fraud rate spikes overnight, in the early-morning window that typically reflects automated card-testing rather than real spending behaviour.
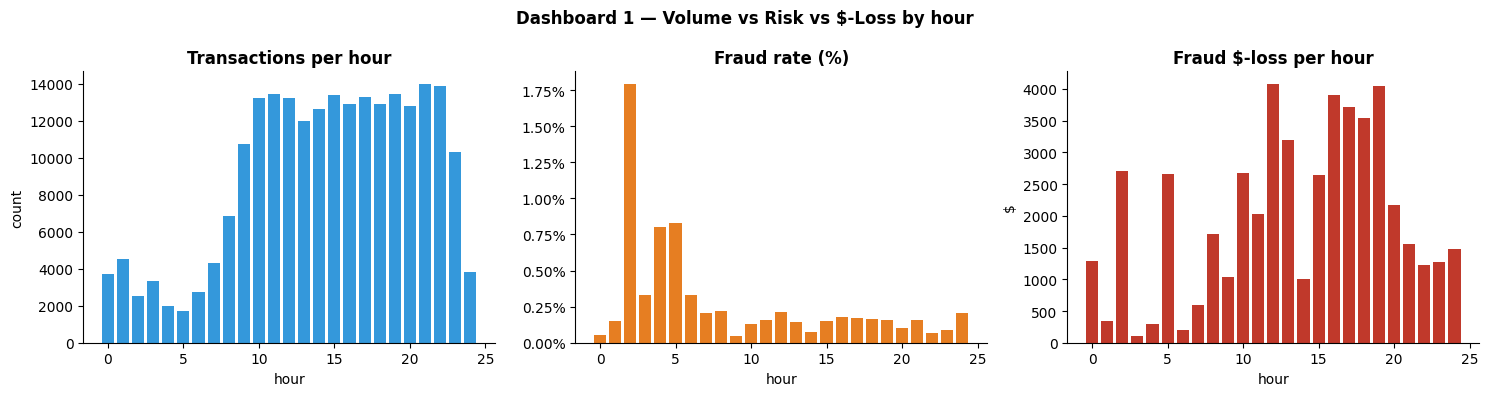
The split between rate and dollars is one of the more useful findings in the dataset. A rate-based view highlights the 2–5am card-testing pattern; a dollar-weighted view points instead at the 10am–8pm window where higher-value fraud blends into legitimate activity. Both views are valid, they simply answer different questions.
hourly = query("""
SELECT CAST((Time/3600) % 24 AS INTEGER) AS hour,
COUNT(*) AS n,
SUM(Class) AS frauds,
100.0*SUM(Class)/COUNT(*) AS fraud_pct,
SUM(CASE WHEN Class=1 THEN Amount ELSE 0 END) AS fraud_dollars
FROM t GROUP BY hour ORDER BY hour
""", t=train)Amount risk: fraud is not the big-ticket event you think it is
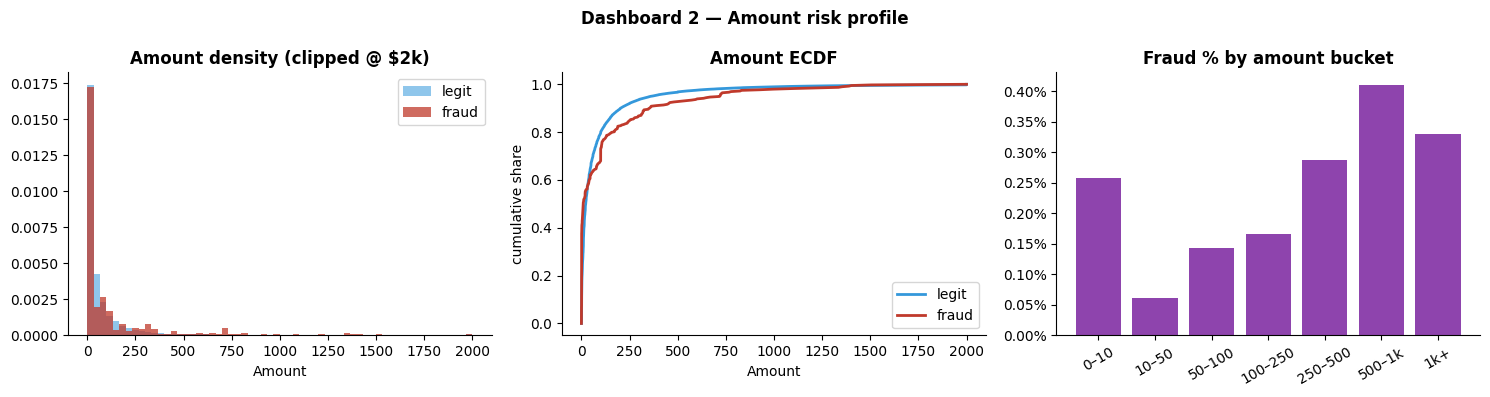
The amount distribution adds a second layer. Fraud is not concentrated only in large purchases; much of it appears in low-value transactions consistent with stolen-card validation. But the fraud rate also rises again in the $500–$1,000 range, which means blanket filters based on 'large' or 'small' amounts would miss part of the real risk structure.
Analytical read
The $500–$1k bucket has the highest single-bucket fraud rate (~0.41%). From a value-protection perspective, a blanket low-amount filter would discard exactly the segment where dollar loss compounds.
Where the signal lives: feature-level analysis
Of the anonymised PCA features V1–V28, only a handful carry the fraud signal. Correlation analysis isolates V17, V14, V12 and V10 as the dominant negative correlates, and V11 and V4 as the strongest positives. The violin plots show visible class separation, which is the precondition for any model to work at all.
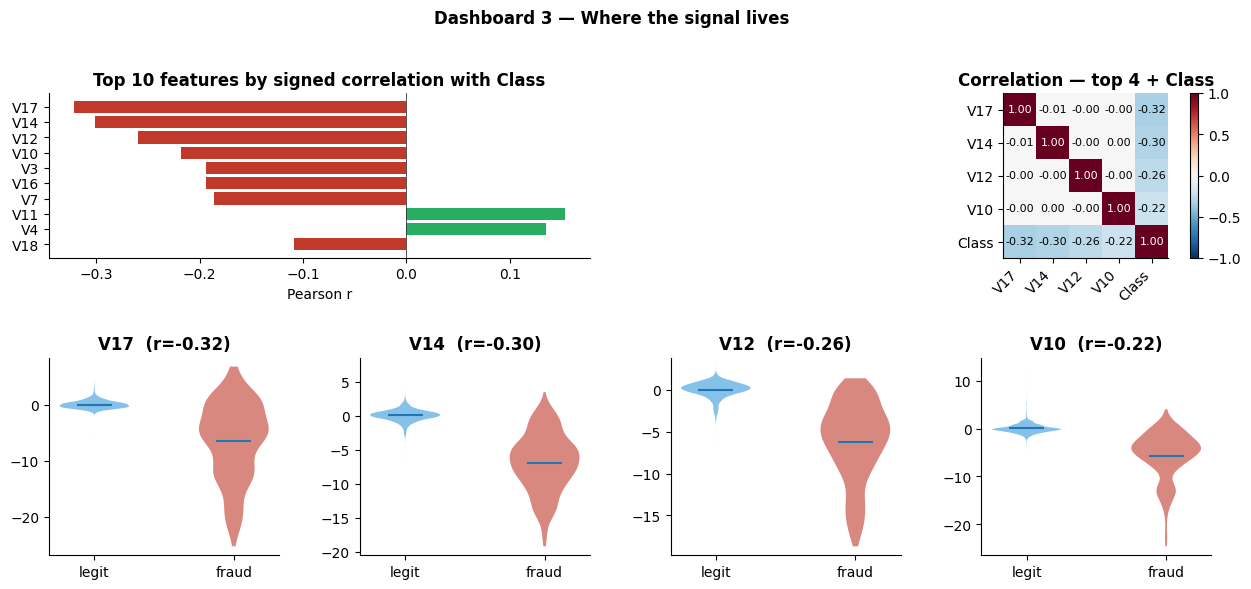
Later, SHAP attribution on the trained model points at the same group of features. That alignment between exploratory EDA and post-hoc model attribution is a useful internal check: the model is learning the structure already visible in the data, not memorising noise.
The review-budget curve: capacity vs recall, before model choice
If transactions are ranked by a single feature's 'fraud-ness' and reviewed up to a fixed daily capacity, how much fraud is recoverable? Sorting by −V14 alone, with no model at all, captures 82% of fraud at 1% review volume and 91% at 10%. A single-feature rule already dominates random review.
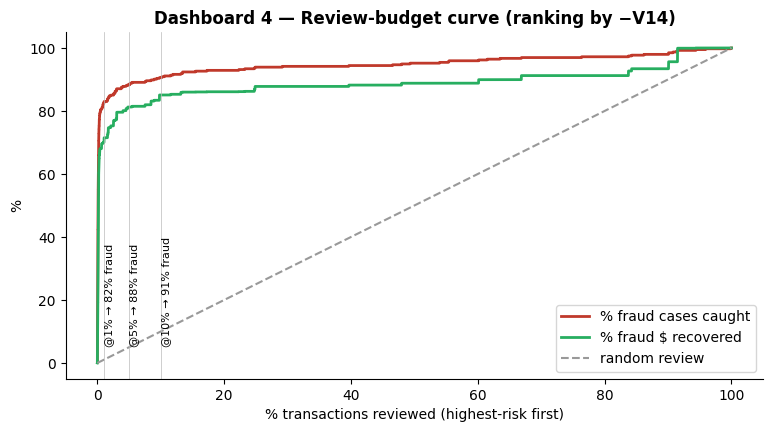
Bound the capacity question first
The review-budget curve forces the capacity-vs-recall trade-off to be quantified before any threshold is tuned. That single bound constrains the model selection and calibration that follow.
The model: boosted trees, calibrated, thresholded by dollars
The champion model is XGBoost, a gradient-boosted tree model that builds many small decision trees in sequence, each one focusing on the mistakes the previous ones made. That matters here because fraud is rarely linear: a suspicious transaction is usually defined by an interaction between latent behaviour patterns, timing and amount, and boosted trees capture those non-linear combinations efficiently.
Raw boosted-tree scores rank transactions well but are not numerically reliable as probabilities. The analysis therefore calibrates with Platt scaling on validation, then sweeps the threshold for net dollars saved (recovered fraud dollars − analyst review cost) rather than using 0.5 by default. The pipeline in plain English: split first so leakage cannot happen, fit preprocessing only on training data, train the ranker, calibrate on validation, then choose the cutoff using a business cost function.
Results, read as decisions
On the held-out test set the headline numbers are strong, but they become more informative when read as decisions rather than scores. The model delivers $2,496.73 in net savings versus a no-model baseline, recovers 64.0% of fraud dollars, catches 89.8% of fraud cases at a calibrated cutoff of 0.1875, reaches 73.33% precision overall, and lands PR-AUC 0.8855 / ROC-AUC 0.9774 with Precision@100 = 0.45.
| Metric | Value | Why it matters |
|---|---|---|
| Net dollars saved | $2,496.73 | Business lift after subtracting false-positive review cost. |
| Fraud dollars recovered | 64.0% | Measures financial recovery, not just event count. |
| Fraud case recall | 89.8% | The model catches almost 9 in 10 fraud events. |
| Precision | 73.33% | Most flagged transactions are truly fraud, the queue is high-purity. |
| PR-AUC | 0.8855 | Best overall ranking metric for this rare-event setting. |
| ROC-AUC | 0.9774 | Strong ranking signal, though less business-relevant than PR-AUC here. |
| Threshold | 0.1875 | Chosen by net-savings optimisation, not by convention. |
| Precision@100 | 0.45 | About 45 real frauds in the top 100 ranked transactions. |
The 26-point gap is the real finding
Case recall is 89.8% but dollar recovery is only 64%. The misses skew to higher-value fraud. If the objective is to protect organisational value rather than maximise event recall, the next iteration should explore cost-sensitive learning or transaction-amount weighting so the model pays more attention to expensive misses.
Segment-level robustness: does the average hide a failing slice?
Overall PR-AUC of 0.886 is a single number. The more useful question is whether it holds across slices (different hours of day, different amount buckets) or whether one cohort drags the average up while another silently fails.
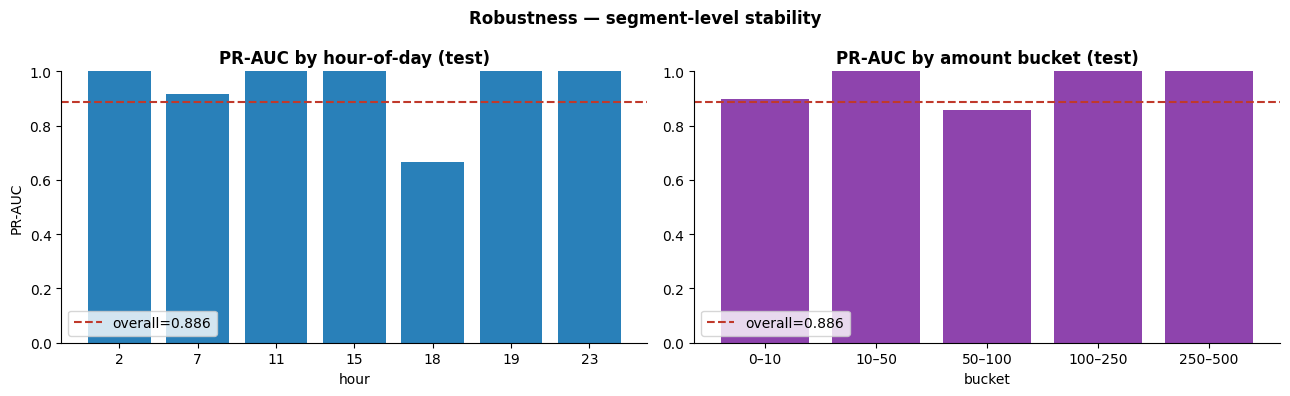
- Most hour-of-day slices hold at PR-AUC 0.9+, the model generalises across the daily cycle.
- The 6pm hour drops to PR-AUC 0.66, a concentrated population of confusing transactions, worth investigating in a follow-up.
- Across amount buckets, only $50–$100 dips below the overall line, and only slightly.
What this analysis does differently
- Split before transform. Stratified train/val/test partitions are created before any scaler, encoder, or feature step runs, leakage is impossible by construction.
- Class imbalance handled, not ignored. No naive SMOTE-everything. scale_pos_weight in XGBoost preserves the legitimate class while up-weighting the rare one during gradient computation.
- Calibrate before thresholding. Raw boosted-tree probabilities are poorly calibrated; Platt scaling on validation makes the threshold sweep meaningful in dollar terms.
- Threshold by net savings. The chosen 0.1875 cutoff is the argmax of (recovered_fraud_dollars − review_cost) on validation, not a default.
- Per-prediction explanations. SHAP values attribute each score to specific features (V14 dominant, V4 supporting), so the model is auditable rather than a black box.
How I built this: a CRISP-DM workflow, notebook to blog
The analysis follows CRISP-DM end-to-end: business understanding first (what does it take to protect transaction value on an imbalanced dataset?), then data understanding, preparation, modelling, evaluation in dollar terms, and finally write-up. The work lives in a strictly sequential Jupyter pipeline (00 → 09), and the final article is assembled as a static site, so the analytical artefacts and the published narrative stay in sync.
- 00–01 Ingestion with DuckDB. Fast profiling and rigorous de-duplication before the train/val/test split, leakage prevention is a structural choice, not a checklist item.
- 02–05 EDA & feature engineering. Locate where fraud concentrates: 2–5 a.m. card-testing spikes vs business-hours dollar loss, and the V17/V14/V12/V10 signal cluster.
- 06 Modelling & calibration. XGBoost with scale_pos_weight to handle the 0.173% base rate natively, then Platt scaling to turn raw margins into trustworthy probabilities.
- 07 Financial thresholding. Sweep the cutoff for max net dollars saved (recovered fraud − $4 review cost per false alarm). SHAP gives each prediction a per-feature explanation.
- 08–09 Reporting. Aggregate to KPIs, export figures to reports/figures/, and build an interactive HTML report at reports/html/index.html.
From notebook to blog: the pipeline exports PNG dashboards (KPIs, temporal volume-vs-risk, SHAP summaries) and markdown drafts in docs/blog/ that talk in KPIs rather than ROC curves. 227,845 transactions, $49k at risk, the 26-point case-vs-dollar gap. The site picks up those drafts and image assets and renders the article you are reading now. DuckDB and XGBoost do the math, Python translates it into dollar impact, and the static build wraps the result into a clean web layout.
Why this way
CRISP-DM keeps the business question (protect organisational value on an imbalanced dataset) in the driver's seat from the first notebook to the last paragraph. Splitting the work as notebooks for analysis and a static site for publication means the analytical artefacts and the published narrative cannot drift apart.
What to build next
- Cost-sensitive training. Pass Amount as the sample weight so the loss natively penalises missing a $2,000 fraud more than a $20 one. Expected lift: close the 26-point case-vs-dollar gap by 5–10 points.
- Time-aware validation. Replace random stratified split with a forward-rolling split that respects transaction time order, the only honest way to estimate next-period performance.
- Drift monitor. Track PR-AUC weekly per hour-of-day and per amount bucket. The 6pm dip in the robustness chart is the canary, the first metric that will move when the fraud pattern shifts.
- Feedback loop. Any reviewed prediction becomes a new labelled example; retrain on a regular cadence. Fraud models decay quickly.
Closing: the technical work serves the business question
The dataset shows where risk concentrates, the model reflects that structure, calibration makes the scores usable, and the threshold is chosen against an explicit cost function. We catch 90% of fraud cases and recover 64% of fraud dollars on the held-out test window, netting $2,497 after review costs. The 26-point gap between case recall and dollar recovery is where the remaining organisational value lives, and where the next iteration should focus.
Rudy Prasetiya
IT GRC, cybersecurity & audit practitioner. Writes about controls that actually hold.

